
《2023中国大模型行研能力评测报告》商汤日日新·商量获评第一
日前,权威研究机构弗若斯特沙利文(Frost & Sullivan, 简称“沙利文”)联合头豹研究院发布《2023年中国大模型行研能力评测报告》。评测结果显示,商汤语言大模型“日日新·商量”(简称:商汤商量)以总分7.73(满分10分)斩获总榜第一,并在报告撰写能力(八大模块)、模型基础能力(行研基础能力)两个子榜位居第一。
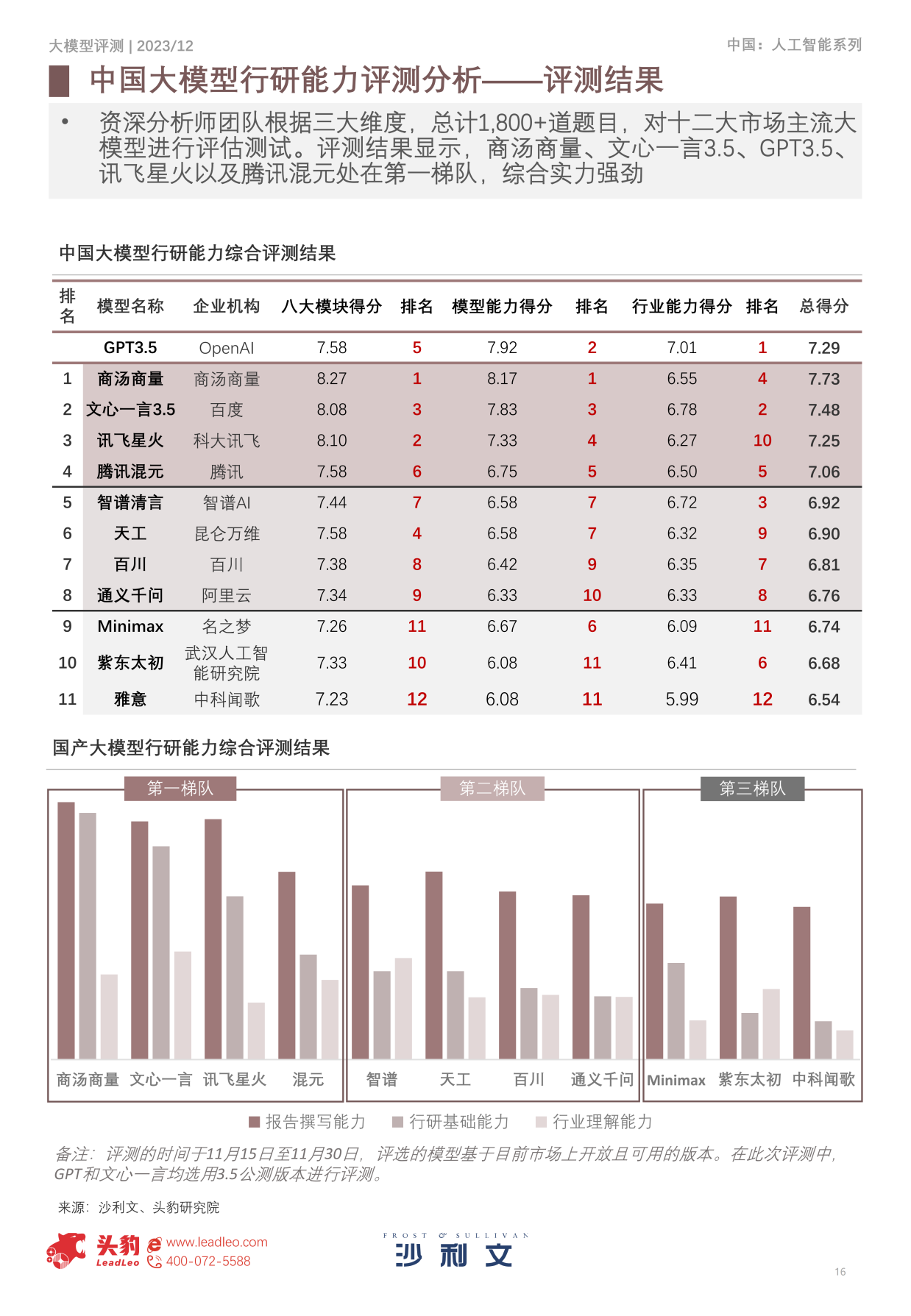
图:中国大模型行研能力综合评测榜单(来源:沙利文)
为全面了解中国大模型在行业研究领域的应用表现,沙利文调动了百人规模的分析师,从研究报告撰写能力、模型基础能力、行业综合理解能力三大核心板块对大模型进行了多维度的综合评估。
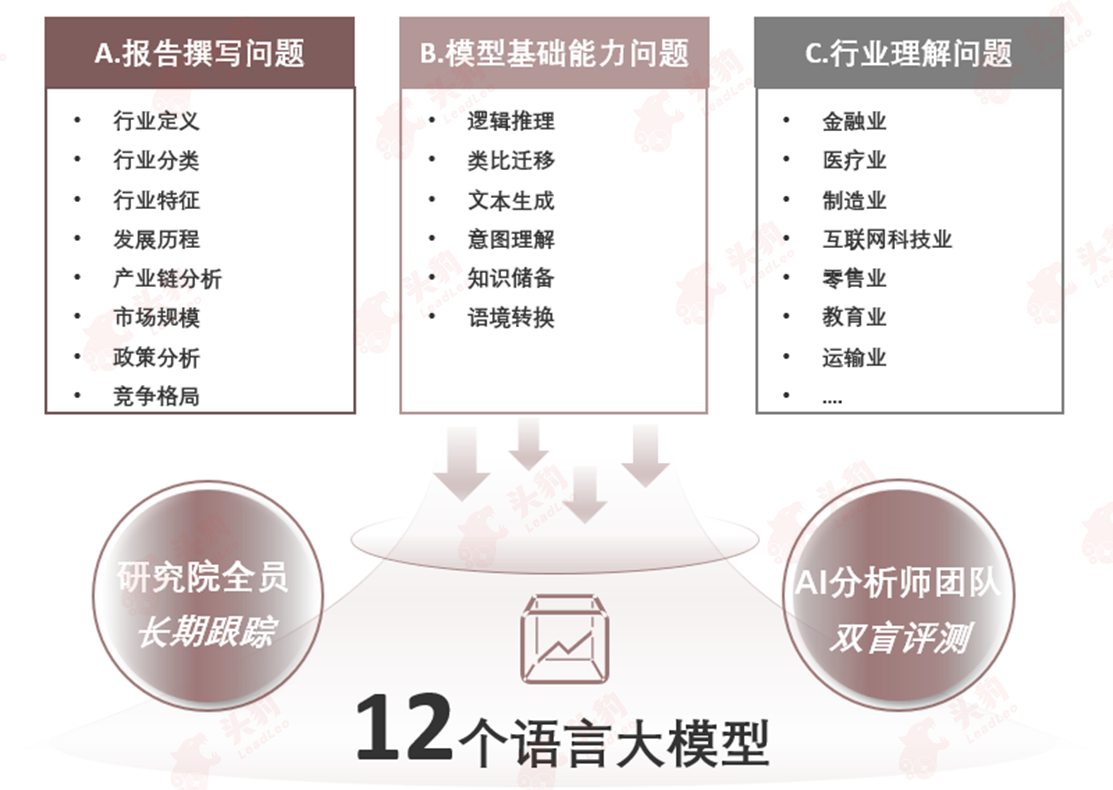
图:大模型行业能力评测方法:报告撰写、模型基础能力、行业理解
(来源:沙利文)
经过模型能力评测,沙利文报告指出,商汤商量作为中国最早推向市场的千亿参数大语言模型之一,在报告撰写能力、模型基础能力等方面均领先其他大模型,不但可以处理各类文本和信息,在协助行业分析师工作时,还可胜任随身综合知识库、高效文本编辑器、数理计算器和简单易用的编程助手等多个角色。
小标题:行研领域内容创作“高门槛”,商汤商量三项“第一”解放行业生产力
内容生成和创作能力是目前大模型最火热的应用场景,并且也是能够直接体现大模型生产力水平的能力。从大模型应用场景来看,无论是知识管理、市场营销、客户服务,还是员工自身日常工作,都需要大模型具有优秀的内容生成和创作能力。Gartner 预测,到2025年,企业30%的营销信息将会由大模型协助生成。
行业研究是通过分析特定行业的定义、竞争格局、市场规模等关键方面,产出深刻洞察和观点,涵盖从宏观的产业层到微观的产品层,各层级决定着相应的研究方法,研究方法论囊括外部宏观因素和内部微观细节的全面分析。其行业特殊性、复杂性、严谨性对大模型的内容生成和创作能力提出了多维度的高要求。
同时,目前行业研究工作依然存在诸多痛点。从基础数据收集到深度分析输出,传统行业研究的流程面临着工具革新滞后、团队知识难以传承、信息溯源复杂性以及研报质量控制的重大挑战。
结合大模型技术,可以协助分析师克服传统行业研究的核心制约因素,通过AI专家访谈、AI内容生成、AI文字校对、AI资料检索等多方面赋能行研行业,显著提升研究的精度和效率,同时加速分析师的专业成长,进一步推动行研数字化进程。
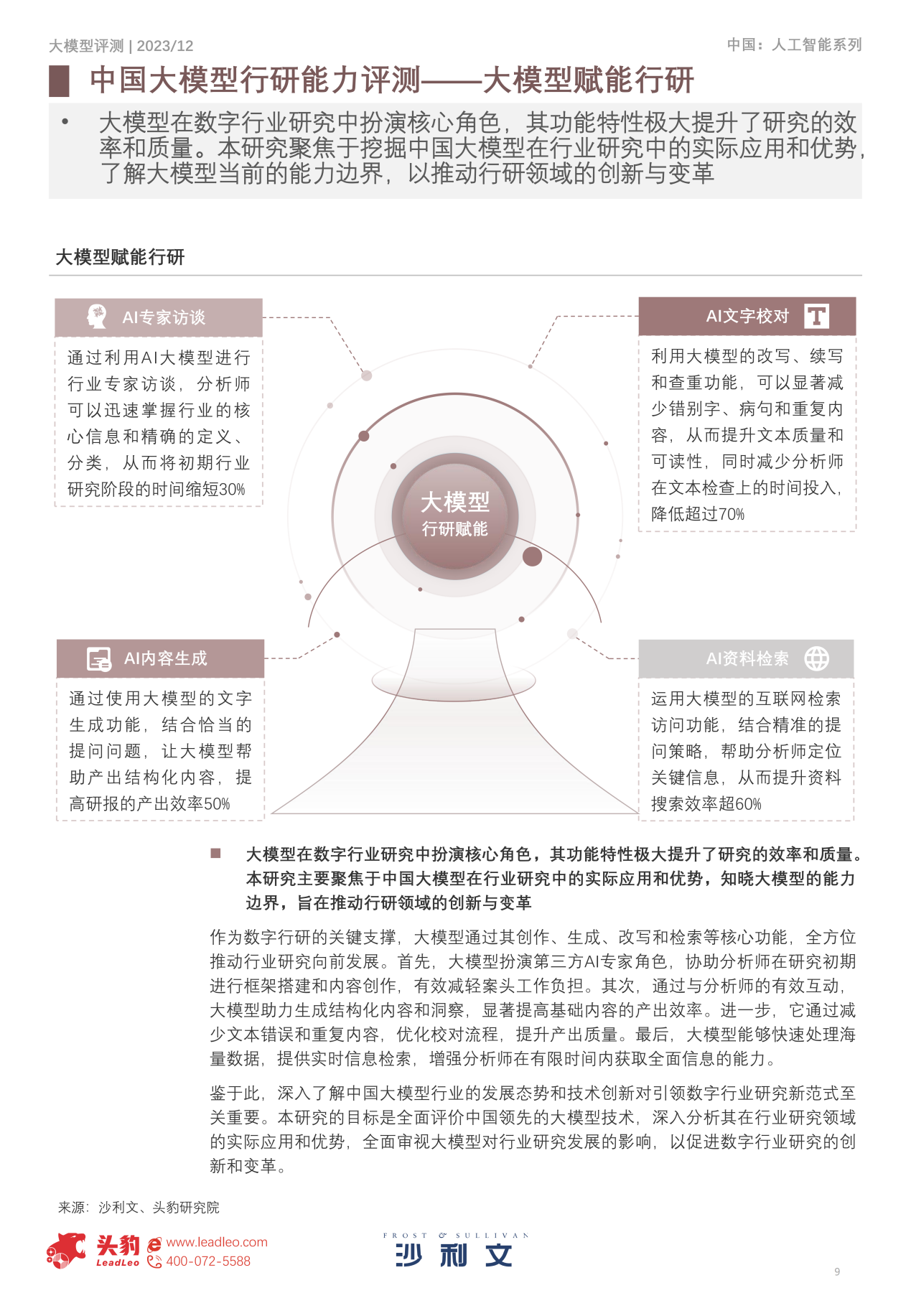
图:大模型赋能行业研究(来源:沙利文)
商汤商量除了在总榜第一,在报告撰写能力的子榜单同样位居第一。此前,沙利文及头豹行企研究的8-D方法论,是一种全面系统的研究方法,包含了八大关键模块,用于对行业进行深入分析。

在这一框架下,百名分析师研磨提炼一套高效的8D模块提问方法,以对模型能力进行评测,商汤商量正是经过了这套方法的检验。沙利文认为,根据大模型报告撰写能力综合热力矩阵图可以看出商汤商量是综合能力最强的模型, 且在各个板块的表现稳定处在前列位置,体现出均衡的能力。
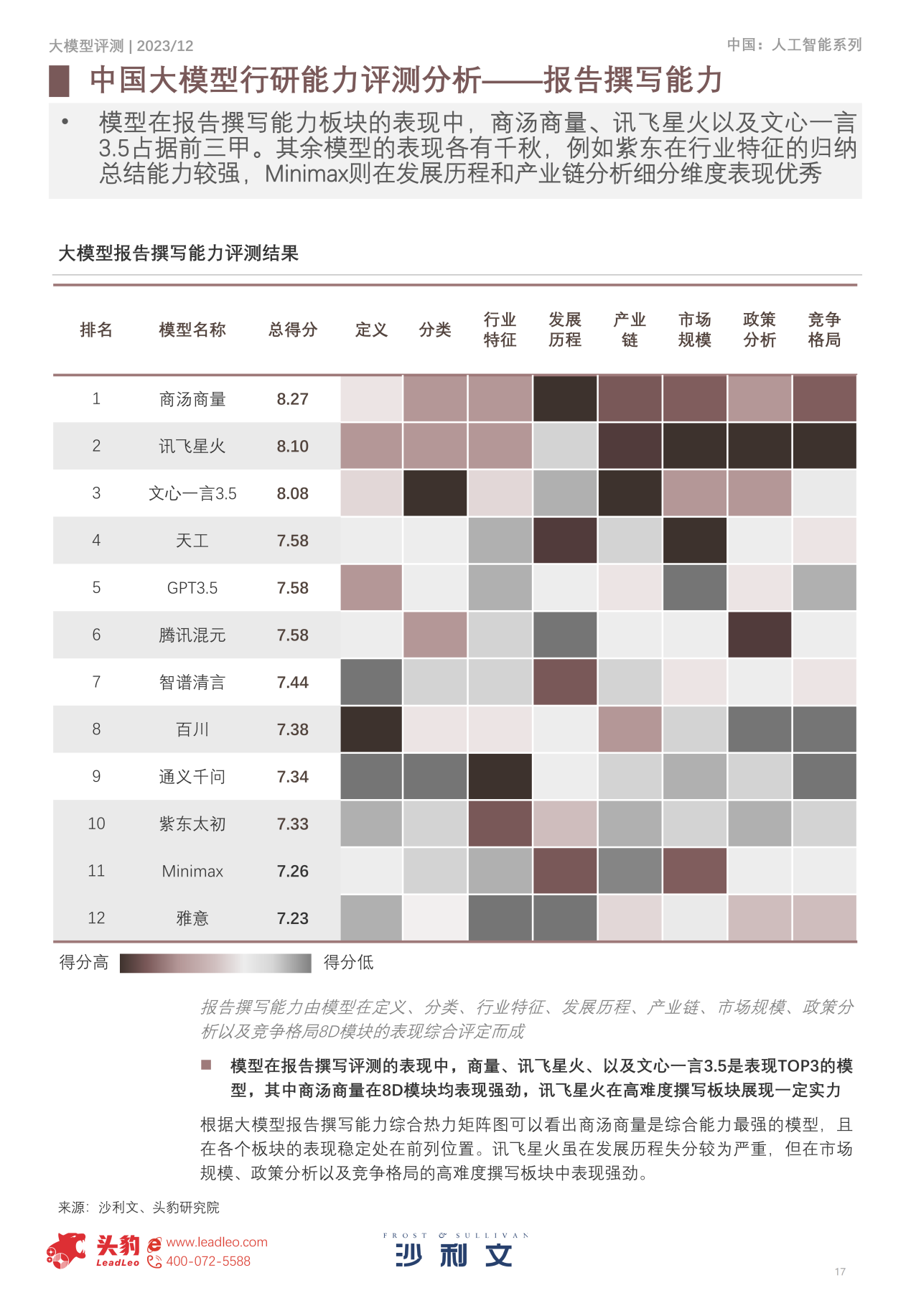
图:大模型的撰写能力评测结果 - 热力矩阵图(来源:沙利文)
另外,在模型基础能力(行研基础能力)子榜中,商汤商量再次夺魁,并在语境转换、文字生成、知识储备等模块排名第一,能够为行业研究提供深度分析和有价值的见解。分析师认为,商汤商量的产出内容能够避免使用非专业词汇,同时确保生成内容的完整性和专业性,从而为用户提供符合要求且令人阅读体验感满意的研究产出物。

图:大模型的模型基础能力(行研基础能力)评测结果 - 热力矩阵图
(来源:沙利文)
小标题:基于AI“三要素”全面深耕模型能力,商汤科技提速生成式AI应用落地
商汤商量取得优秀的评测结果,离不开对基模型能力的长期耕耘和提升。首先,依托丰沛AI算力的SenseCore 商汤AI大装置,通过软件、硬件、工程化系统以服务大模型迭代为目标的研发配合,保障了大模型的高频迭代,以及不断精炼的训练配方。
其次,商汤在积累巨大的原始语料数据的基础上,通过高精度的分类器和人工精细化清洗的方式,提炼出高质量的数据,进而训练性能强大、价值观对齐的大模型。现在,商汤的高质量训练数据的每个月产出量,已经达到2万亿Tokens。
在此之前,新华社研究院发布《人工智能大模型体验报告3.0》,报告显示,商汤“商量SenseChat”在定量实测的情商维度上,位居全部10款大模型第一,并在定性评估中入选大模型市场未来领袖象限。借助丰厚、领先的算力和数据资源,商汤不断优化迭代大模型能力,提升生产力水平,未来将进一步引领行业研究进入一个效率更高和质量更优的新产出范式,以促进数字行业研究的创新和变革。
放眼未来,商汤科技将持续创造领先的大模型落地和生成式AI应用生态,向通用人工智能(AGI)持续迭代,用我们的创新力为AGI时代的到来做出努力。